| Mysql.8.0 与 MongoDB.4.2大数据量查询性能对比 | 您所在的位置:网站首页 › 大数据 mysql › Mysql.8.0 与 MongoDB.4.2大数据量查询性能对比 |
Mysql.8.0 与 MongoDB.4.2大数据量查询性能对比
|
目录 摘要 1测试环境以及测试用例设计 1.1测试环境 1.2测试用例设计 2百万级数据量性能测试对比 2.1数据总量 2.2性能测试报告 2.3图表分析与总结 3 千万级数据量性能测试对比 3.1 数据总量 3.2 性能测试报告 3.1数据总量 3.2性能测试报告 3.3图表分析 4 总结 摘要项目中使用MySQL存储采集的数据,但是查询遇到了性能瓶颈,前一段时间曾预研使用MongoDB来存储采集数据量比较大的几张表,这里总结出来分享给大家参考下。项目采集数据的特点:数据会不断增加,查询也比较多。 1测试环境以及测试用例设计 1.1测试环境 Mysql 和Mongodb 都是 4C/8G,测试接口都是通过Spring boot 微服务rest接口测试。MySQL 数据中的表和mongodb中集合都设创建了相同的索引。其中create_time 都使用了降序索引。 1.1.1 Mysql 索引
1.1.2MongoDB索引
1.2.1时间范围分页查询参数 /result/{page}/{size}/{startTime}/{endTime} 1.2.2根据任务信息查询参数: /conditionOne/{page}/{size}/{powerDeviceId}/{taskId} 1.2.3执行批次范围查询参数: /conditionTwo/{page}/{size}/{batchIdList} 1.2.4执行任务与批次范围查询参数: /conditionThree/{page}/{size}/{batchIdList}/{taskIdList} 1.2.5聚合查询,采集计划前10个批次数据聚合: /aggregate/{planId} 会使用group by 和 order by 以及limit。 2百万级数据量性能测试对比 2.1数据总量
2.2.1用例1时间范围分页查询 请求参数: /mongodb/result/20/20/2019-09-01/2019-09-30 /mysql/result/20/20/2019-09-01/2019-09-30连续两次性能测试报告:
2.2.2用例2任务信息查询 请求参数: /mongodb/conditionOne/20/20/611607718939246592/611680047597752372 /mysql/conditionOne/20/20/611607718939246592/611680047597752372连续两次性能测试报告:
2.2.3用例3批次范围查询 请求参数: /mysql/conditionTwo/10/20/1001,1002,1003,1004,1005,1027 /mongodb/conditionTwo/10/20/1001,1002,1003,1004,1005,1027连续两次性能测试报告:
2.2.4用例4任务与批次范围查询 请求参数: /mongodb/conditionThree/1/20/1001,1002,1003,1004,1005,1027/611680047593558016,611680047593558017,611680047593558020,611680047593558021,611680047593558024,611680047593558025,611680047593558030,611680047593558031,611680047593558032,611680047593558033,611680047593558035,611680047593558036,611680047593558037,611680047593558038,611680047593558039,611680047593558040 /mysql/conditionThree/1/20/1001,1002,1003,1004,1005,1027/611680047593558016,611680047593558017,611680047593558020,611680047593558021,611680047593558024,611680047593558025,611680047593558030,611680047593558031,611680047593558032,611680047593558033,611680047593558035,611680047593558036,611680047593558037,611680047593558038,611680047593558039,611680047593558040连续两次性能测试报告:
2.2.5用例5聚合查询 请求参数: /mysql/aggregate/620656410385203201 /mongodb/aggregate/620656410385203201连续两次性能测试报告:
2.3图表分析与总结 2.3.1查询时间对比 以50%为分割线,占比少的说明效率高。用第二次性能测试采集到的性能数据来对比。
2.3.2 吞吐量对比 以50%为分割线,占比多的说明吞吐量高。用第二次性能测试采集到的性能数据来对比。
2.3.3 小结 (1)从平均响应时间来看,查询条件较少的情况下MySQL占据优势,mongodb在查询条件越多的情况下,越占据优势,因为查询条件越多,筛选的数据会比较少,可以有效利用内存。但是优势不是太明显。 (2)从吞吐量上来看,mongodb占据优势,但是除了任务信息查询以外,其他类型查询的优势不是太明显。
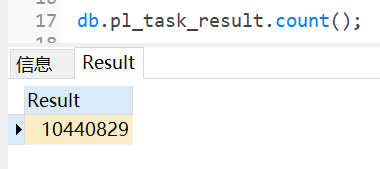
3 千万级数据量性能测试对比 注:下面的测试数据没有分表或者分片。 3.1 数据总量
注:下面的测试数据没有分表或者分片。 3.1数据总量
3.2.1用例1时间范围分页查询 请求参数: /mongodb/result/20/20/2019-09-01/2019-09-30 /mysql/result/20/20/2019-09-01/2019-09-30连续两次性能测试报告:
3.2.2用例2任务信息查询 请求参数: /mongodb/conditionOne/20/20/611607718939246592/611680047597752372 /mysql/conditionOne/20/20/611607718939246592/611680047597752372连续两次性能测试报告:
请求参数增加批次ID: /mongodb/conditionOne/20/20/611607718939246592/611680047597752372/30194 /mysql/conditionOne/20/20/611607718939246592/611680047597752372/30194连续两次性能测试报告:
3.2.3用例3批次范围查询 请求参数: /mysql/conditionTwo/10/20/ 30199,30198,30197,30196,30195,30194 /mongodb/conditionTwo/10/20/ 30199,30198,30197,30196,30195,30194连续两次性能测试报告:
3.2.4用例4任务与批次范围查询 请求参数: /mongodb/conditionThree/1/20/1001,1002,1003,1004,1005,1027/611680047593558016,611680047593558017,611680047593558020,611680047593558021,611680047593558024,611680047593558025,611680047593558030,611680047593558031,611680047593558032,611680047593558033,611680047593558035,611680047593558036,611680047593558037,611680047593558038,611680047593558039,611680047593558040 /mysql/conditionThree/1/20/1001,1002,1003,1004,1005,1027/611680047593558016,611680047593558017,611680047593558020,611680047593558021,611680047593558024,611680047593558025,611680047593558030,611680047593558031,611680047593558032,611680047593558033,611680047593558035,611680047593558036,611680047593558037,611680047593558038,611680047593558039,611680047593558040连续三次性能测试报告:
3.2.5用例5聚合查询 请求参数: /mysql/aggregate/620656410385203201 /mongodb/aggregate/620656410385203201连续两次性能测试报告:
MySQL手动跑了下:至少需要27S。
这个用例跟表结构设计有关系,数据采集主表 没有添加采集计划的主键plan_id,导致主表根据plan_id聚合查询的时候,MySQL需要使用子查询,如果添加上主键id,并且都根据主键来做聚合计算。应该是下面测试结果:有点奇怪,mongodb的执行效率降低了,但是MySQL的执行效率增加了。对于mongodb来说,主要是过滤条件太少,导致使用磁盘排序。
3.3图表分析 3.3.1查询时间对比 以50%为分割线,占比少的说明效率高。用第二次性能测试采集到的性能数据来对比。
3.3.2吞吐量对比 以50%为分割线,占比多的说明吞吐量高。用第二次性能测试采集到的性能数据来对比。
3.3.3小结 数据量增加到千万的时候,响应时间上升很多和吞吐量下降很多。需要分表或者分片。 (1)从平均响应时间来看,mongodb占据绝对优势。 (2)从吞吐量上来看,mongodb占据绝对优势。
(4)对于千万或者更大的数据量,应该是要分区或分片,同时考虑分区容错性。如下图,mongodb属于CP,同时满足一致性(C,Consistency)、分区容错性(P,Partition Tolerance)。MySQL属于CA,同时满足一致性(C,Consistency)、可用性(A, Availability)。
|




































【本文地址】